Hvad er tegnkodninger som ANSI og Unicode, og hvordan adskiller de sig?
ASCII, UTF-8, ISO-8859 ... Du har måske set disse underlige monikere flydende rundt, men hvad gør de betyder faktisk? Læs videre, da vi forklarer, hvilken tegnkodning er, og hvordan disse akronymer vedrører den almindelige tekst, vi ser på skærmen.
Grundlæggende byggesten
Når vi taler om skriftsprog, taler vi om bogstaver, der er byggestenene af ord, som derefter bygger sætninger, afsnit osv. Bogstaver er symboler, der repræsenterer lyde. Når du taler om sprog, taler du om grupper af lyde, der kommer sammen for at danne en slags mening. Hvert sprogsystem har et komplekst sæt regler og definitioner, der styrer disse betydninger. Hvis du har et ord, er det ubrugeligt, medmindre du ved, hvilket sprog det er fra, og du bruger det med andre, der taler dette sprog.

(Sammenligning af Grantha, Tulu og Malayalam scripts, Billede fra Wikipedia)
I verden af computere bruger vi udtrykket "karakter". Et tegn er et abstrakt koncept, der er defineret af specifikke parametre, men det er den grundlæggende betydningsenhed. Latin'en 'A' er ikke den samme som en græsk 'alfa' eller en arabisk 'alif', fordi de har forskellige sammenhænge - de er fra forskellige sprog og har lidt forskellige udtaler - så vi kan sige, at de er forskellige tegn. Den visuelle repræsentation af et tegn kaldes en "glyph" og forskellige sæt glyfer kaldes skrifttyper. Grupper af tegn tilhører et "sæt" eller et "repertoire".
Når du skriver et stykke, og du ændrer skrifttypen, ændrer du ikke bogstavets fonetiske værdier, du ændrer hvordan de ser ud. Det er bare kosmetisk (men ikke ubetydeligt!). Nogle sprog, som gamle egyptiske og kinesiske, har ideogrammer; disse repræsenterer hele ideer i stedet for lyde, og deres udtalelser kan variere over tid og afstand. Hvis du erstatter et tegn til et andet, erstatter du en ide. Det er mere end bare at skifte bogstaver, det ændrer et ideogram.
Tegnkodning

(Billede fra Wikipedia)
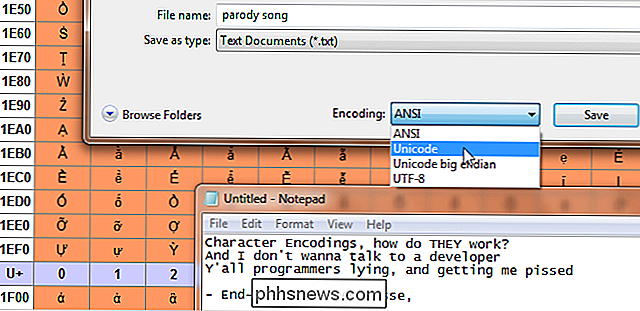
Når du skriver noget på tastaturet eller lægger en fil, hvordan kan computeren vide, hvad der skal vises? Det er hvad tegnkodning er til. Tekst på din computer er faktisk ikke bogstaver, det er en række parrede alfanumeriske værdier. Tegnkodningen virker som en nøgle, for hvilke værdier svarer til hvilke tegn, ligesom hvordan ortografien dikterer hvilke lyde, der svarer til hvilke bogstaver. Morse-kode er en slags tegnkodning. Det forklarer, hvordan grupper af lange og korte enheder som bip repræsenterer tegn. I Morse-koden er tegnene kun engelske bogstaver, tal og fuldstop. Der er mange computer tegn kodninger, der oversætter til bogstaver, tal, accent mærker, tegnsætningstegn, internationale symboler osv.
Ofte om dette emne bruges udtrykket "kode sider" også. De er i det væsentlige karakterkodninger som brugt af bestemte virksomheder, ofte med små ændringer. For eksempel er kodeksen Windows 1252 (tidligere kendt som ANSI 1252) en modificeret form af ISO-8859-1. De bruges mest som et internt system til at henvise til standard og modificerede tegnkoder, der er specifikke for de samme systemer. I begyndelsen var tegnkodning ikke så vigtigt, fordi computere ikke kommunikerede med hinanden. Med internettet stigende til fremtrædende og netværk er en fælles begivenhed, er det blevet en stadig vigtigere af vores daglige liv uden at vi selv forstår det.
Mange forskellige typer
(Billede fra sarah sosiak)
Der er mange forskellige karakterkodninger derude, og der er mange grunde til det. Hvilket tegnkodning du vælger at bruge afhænger af, hvad dine behov er. Hvis du kommunikerer på russisk, er det fornuftigt at bruge en tegnkodning, der understøtter cyrillisk godt. Hvis du kommunikerer på koreansk, så vil du have noget, der repræsenterer Hangul og Hanja godt. Hvis du er en matematiker, vil du have noget, der har alle de videnskabelige og matematiske symboler, der repræsenteres godt, såvel som de græske og latinske glyfer. Hvis du er en prankster, kan du måske få gavn af opadgående tekst. Og hvis du vil have alle disse typer dokumenter til at blive vist af en given person, vil du have en kodning, der er ret almindelig og let tilgængelig.
Lad os se på nogle af de mere almindelige.

(Uddrag af ASCII-tabel, Billede fra asciitable.com)
- ASCII - Den amerikanske standardkode for informationsudveksling er en af de ældre tegnkoder. Det blev oprindeligt udformet baseret på telegrafiske koder og udviklet sig over tid til at omfatte flere symboler og nogle nu forældede ikke-trykte kontrol tegn. Det er nok så grundlæggende som du kan få i form af moderne systemer, da det er begrænset til det latinske alfabet uden accenterede tegn. Dens 7-bit kodning tillader kun 128 tegn, hvorfor der er flere uofficielle varianter i brug over hele verden.
- ISO-8859 - Den Internationale Standardiseringsorganisation's mest udbredte gruppe af tegnkoder er nummer 8859 Hver enkelt kodning betegnes med et tal, der ofte er præfikset af en beskrivende moniker, f.eks ISO-8859-3 (Latin-3), ISO-8859-6 (Latin / Arabisk). Det er en superset af ASCII, hvilket betyder, at de første 128 værdier i kodningen er de samme som ASCII. Det er dog 8-bit, og giver mulighed for 256 tegn, så det bygger sig væk derfra og indeholder et meget bredere udvalg af tegn, hvor hver specifikke kodning fokuserer på et andet sæt kriterier. Latin-1 inkluderede en masse accentede bogstaver og symboler, men blev senere erstattet af et revideret sæt kaldet Latin-9, som indeholder opdaterede glyfer som Euro-symbolet.
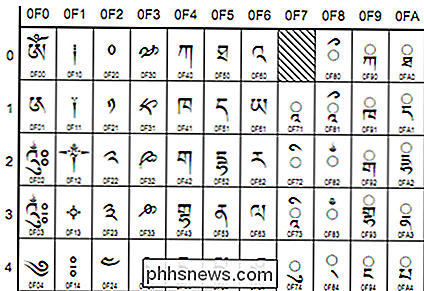
(Uddrag af tibetansk script, Unicode v4, fra unicode.org)
- Unicode - Denne kodningsstandard tager sigte på universalitet. Det indeholder i øjeblikket 93 scripts arrangeret i flere blokke, med mange flere i værkerne. Unicode fungerer anderledes end andre tegnsæt, fordi i stedet for direkte kodning for en glyph, er hver værdi rettet videre til et "kodepunkt". Disse er hexadecimale værdier, der svarer til tegn, men glyphs selv er tilvejebragt på en fri måde af programmet , f.eks. din webbrowser. Disse kodepunkter er almindeligt afbildet som følger: U + 0040 (som oversætter til '@'). Specifikke kodninger under Unicode-standarden er UTF-8 og UTF-16. UTF-8 forsøger at tillade maksimal kompatibilitet med ASCII. Det er 8-bit, men giver mulighed for alle tegnene via en substitutionsmekanisme og flere par værdier pr. Tegn. UTF-16 grøfter perfekt ASCII-kompatibilitet til en mere komplet 16-bit kompatibilitet med standarden.
- ISO-10646 - Dette er ikke en faktisk kodning, kun et tegnsæt af Unicode, der er standardiseret af ISO. Det er mest vigtigt, fordi det er det karakterrepertoire, der bruges af HTML. Nogle af de mere avancerede funktioner, der leveres af Unicode, der tillader collation og højre til venstre sammen med venstre til højre scripting mangler. Alligevel fungerer det meget godt til brug på internettet, da det giver mulighed for brugen af en lang række scripts og giver browseren mulighed for at fortolke glyphs. Dette gør lokalisering noget lettere.
Hvilken kodning skal jeg bruge?
Nå arbejder ASCII for de fleste engelsktalende, men ikke for meget andet. Oftere ser du ISO-8859-1, som fungerer for de fleste vesteuropæiske sprog. De andre versioner af ISO-8859 arbejder for cyrillisk, arabisk, græsk eller andre specifikke scripts. Men hvis du vil vise flere scripts i samme dokument eller på samme webside, giver UTF-8 mulighed for meget bedre kompatibilitet. Det virker også rigtig godt for folk, der bruger ordinære tegnsætning, matematiske symboler eller off-the-cuff-tegn, såsom firkanter og afkrydsningsfelter.

(Flere sprog i et dokument, Skærmbillede af gujaratsamachar.com)
Der er ulemper for hvert sæt, dog. ASCII er begrænset i tegnsætningstegnene, så det virker ikke utroligt godt for typografisk korrekte redigeringer. Har du nogensinde skrevet kopi / indsæt fra Word kun for at have nogle mærkelige kombinationer af glyfer? Det er ulempen med ISO-8859, eller mere korrekt, den formodes at fungere sammen med OS-specifikke kode sider (vi kigger på DIG, Microsoft!). UTF-8s største ulempe er manglen på ordentlig støtte til redigering og udgivelse af applikationer. Et andet problem er, at browsere ofte ikke fortolker og bare viser byteordmærket for et UTF-8-kodet tegn. Dette resulterer i, at uønskede glyfer vises. Og selvfølgelig er det svært for browsere at gøre dem korrekt, og for at søgemaskinerne kan indeksere dem korrekt, og ved at erklære en kodning og brug af tegn fra en anden uden at erklære / henvise dem korrekt på en webside.
For dine egne dokumenter, manuskripter og så videre kan du bruge alt hvad du behøver for at få arbejdet gjort. For så vidt som internettet går, ser det ud til, at de fleste er enige om at bruge en UTF-8-version, der ikke bruger et byteordre, men det er ikke helt enstemmigt. Som du kan se, har hver tegnkodning sin egen brug, kontekst og styrker og svagheder. Som en slutbruger vil du sandsynligvis ikke skulle klare det her, men nu kan du tage det ekstra skridt fremad, hvis du vælger det.

Hvad er RSS, og hvordan kan jeg drage fordel af at bruge det?
Hvis du forsøger at holde øje med nyheder og indhold på flere websteder, står du over for den endeløse opgave at besøge disse websteder for at kontrollere nyt indhold. Læs videre for at lære om RSS, og hvordan det kan levere indholdet rigtigt til dit digitale dørtrin. På internettet er indholdet på nettet smukt forbundet og tilgængeligt, men på trods af sammenhængen mellem det hele, finder vi stadig ofte besøg dette websted, så det websted, så et andet websted, alt for at se efter opdateringer og få det indhold, vi ønsker.

Sådan streamer du videoer og musik til tv'et i dit hotelværelse
Hotelværelserne har stadig fjernsyn, og du kan sætte dem i brug, når du rejser. Hvorfor bruge din bærbare computer, smartphone eller tablet, når du kan se ting søn den større skærm? Vi taler om rekord, der er moderne moderne tv med HDMI-porte på bagsiden her. Ældre tv'er uden HDMI-porte vil være mere problemer.



